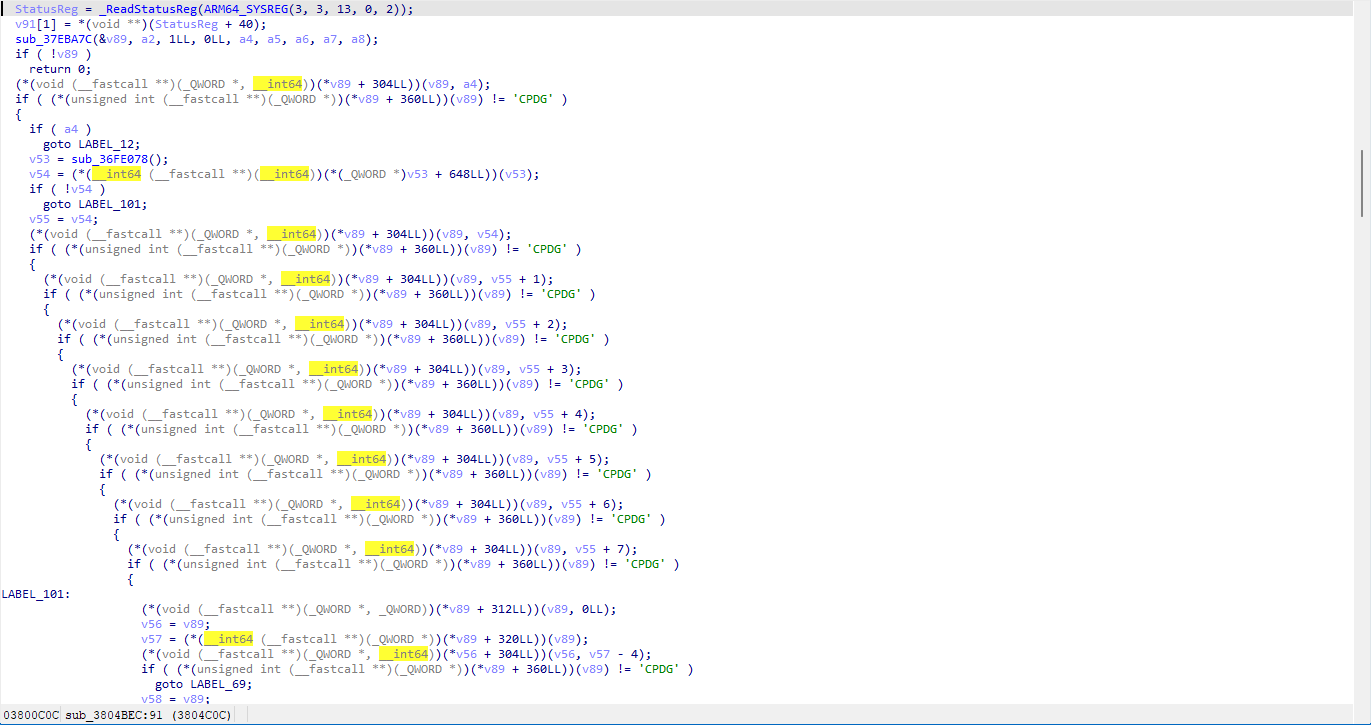
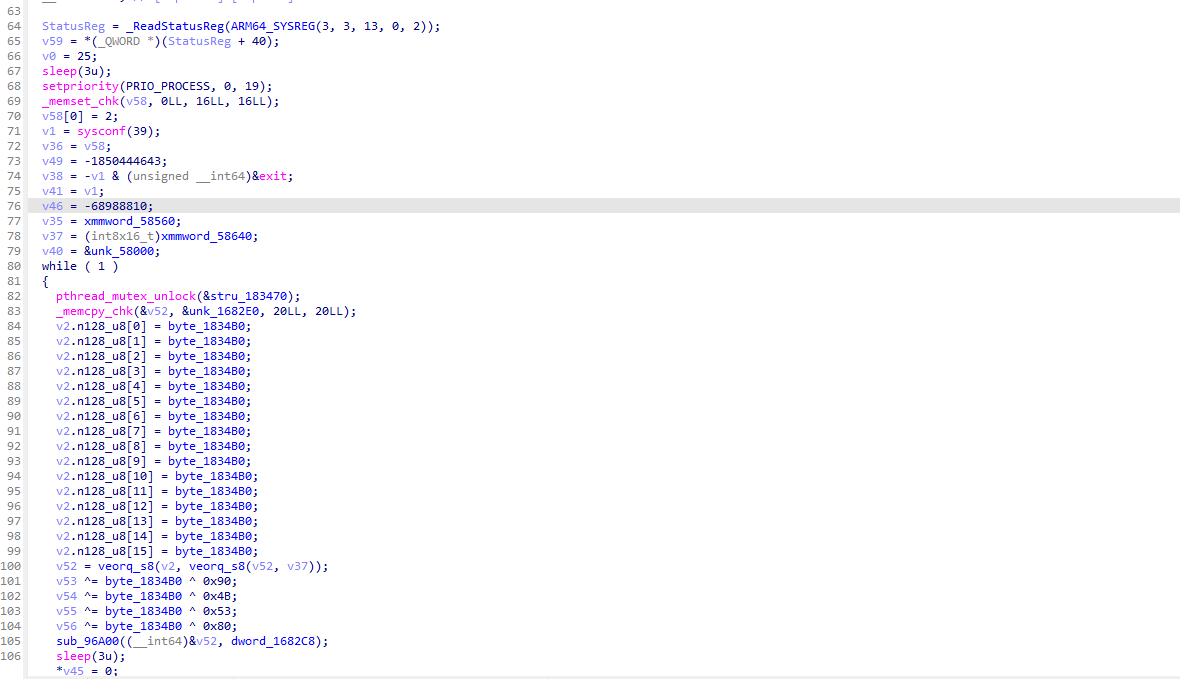
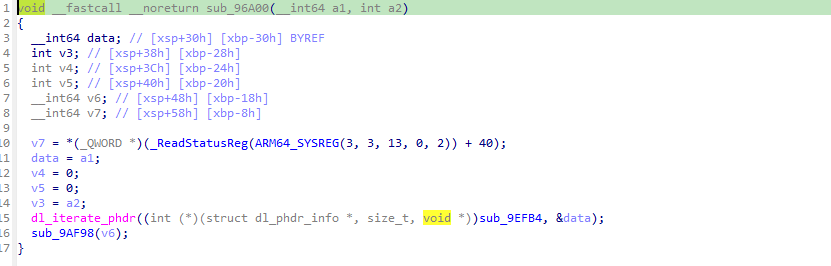
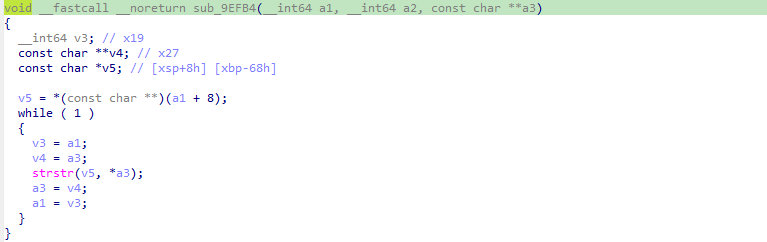
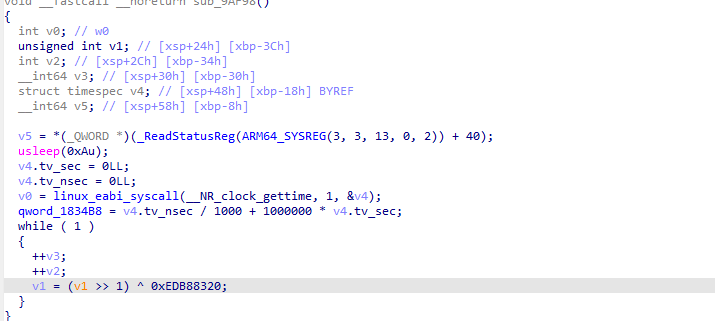
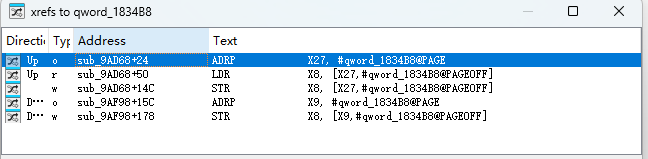
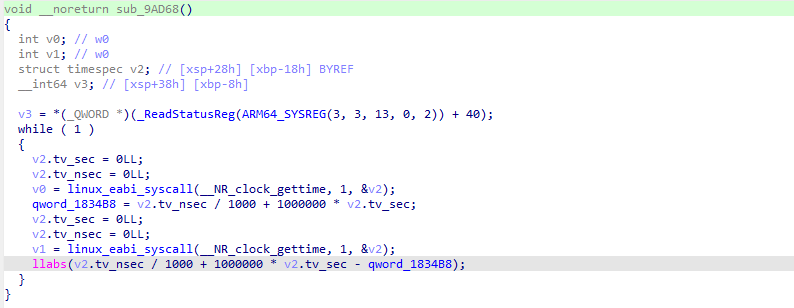
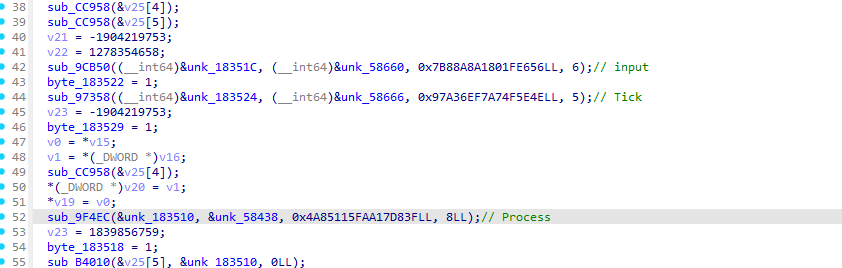
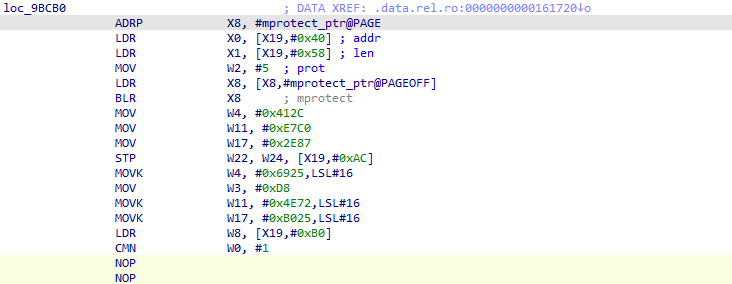
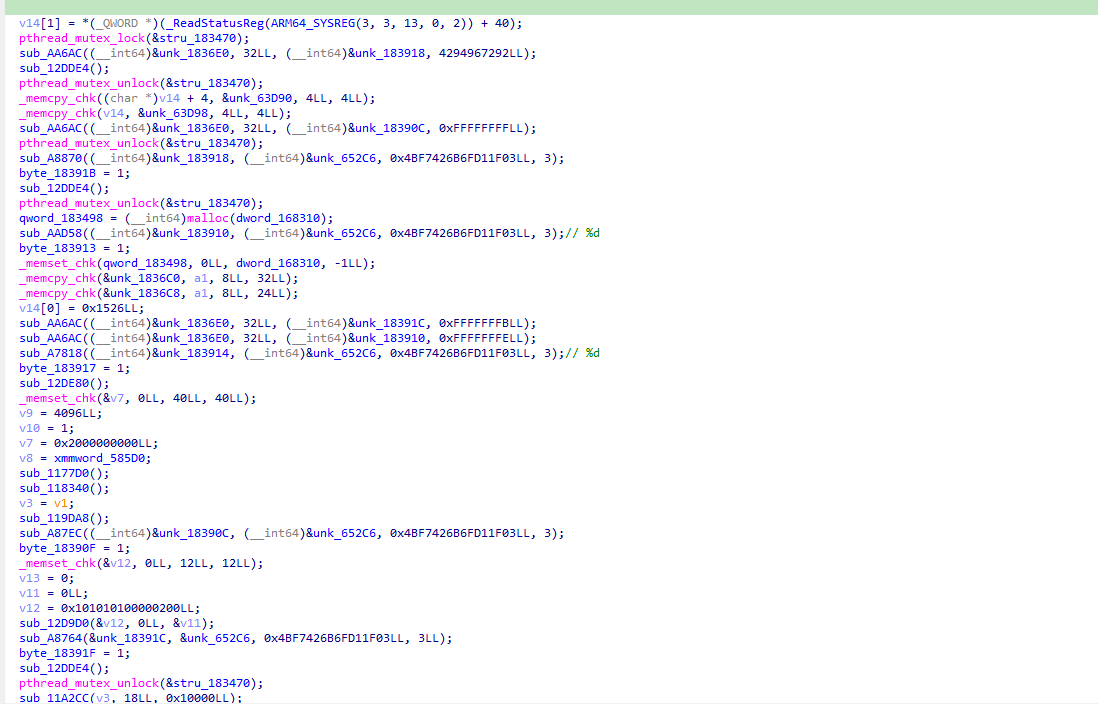
defdecrypt_pck_index(pck_path: Path, key: bytes) -> list[dict]: """Decrypt and parse a PCK file index, returning list of file entries.""" data = pck_path.read_bytes() off = 0
magic = data[off:off + 4]; off += 4 if magic != b"GDPC": raise ValueError(f"Invalid magic: {magic}")
major, minor, patch, rev = struct.unpack_from("<IIII", data, off); off += 16 flags = struct.unpack_from("<I", data, off)[0]; off += 4
ifnot (flags & 1): print("PCK index is not encrypted") return []
_padding = struct.unpack_from("<Q", data, off)[0]; off += 8
if major == 3: seek_offset = struct.unpack_from("<Q", data, off)[0]; off += 8 off = seek_offset
nfiles = struct.unpack_from("<I", data, off)[0]; off += 4
md5_expected = data[off:off + 16]; off += 16 plain_len = struct.unpack_from("<Q", data, off)[0]; off += 8 iv = data[off:off + 16]; off += 16 ciphertext = data[off:off + plain_len]
plaintext = aes256_cfb_decrypt(key, iv, ciphertext)[:plain_len]
if hashlib.md5(plaintext).digest() != md5_expected: raise ValueError("PCK index MD5 mismatch")
bit 31 bit 8 bit 7 bit 6 bit 0 ┌──────────────────────────┬─────┬──────────────────────┐ │ data (24 bits) │ 0x80│ token_type (7 bits) │ └──────────────────────────┴─────┴──────────────────────┘
# Compute token section offset from the end (avoids parsing idents/consts) # Layout: [header 16B] [idents] [consts] [line_starts n_lines*8] [column_info n_lines*8] [tokens n_tokens*8] token_section_size = n_tokens * 8 off = len(decompressed) - token_section_size remapped_count = 0 unknown_types = set()
for i inrange(n_tokens): tok_val = struct.unpack_from('<I', decompressed, off)[0] tok_type = tok_val & 0x7F tok_upper = tok_val & ~0x7F# preserve data and flag bits
if tok_type in game_to_std: std_type = game_to_std[tok_type] new_val = tok_upper | (std_type & 0x7F) struct.pack_into('<I', decompressed, off, new_val) if tok_type != std_type: remapped_count += 1 else: unknown_types.add(tok_type)
for root, dirs, files in os.walk(input_dir): for f in files: if f.endswith('.gdc'): in_path = os.path.join(root, f) rel_path = os.path.relpath(in_path, input_dir) out_path = os.path.join(output_dir, rel_path)
remapped, unknown = parse_and_remap_gdc(in_path, out_path) total_files += 1 total_remapped += remapped status = f" {rel_path}: {remapped} tokens remapped" if unknown: status += f" (UNKNOWN types: {unknown})" print(status)
print(f"\nDone: {total_files} files, {total_remapped} total tokens remapped")
if __name__ == "__main__": main()
至此,终于可以通过 gdre_tools 得到源码了!
*.gd 文件分析
Trigger1 — 示例 Flag(PART0)
1 2 3 4 5 6 7
func _kc(): var _bp = get_overlapping_bodies() if _bp.size() < 1: return if str(get_path()) != "/root/TownScene/Trigger1": return var _lb = get_node("/root/TownScene/Label2") _lb.text = "flag{sec2026_PART0_example}"
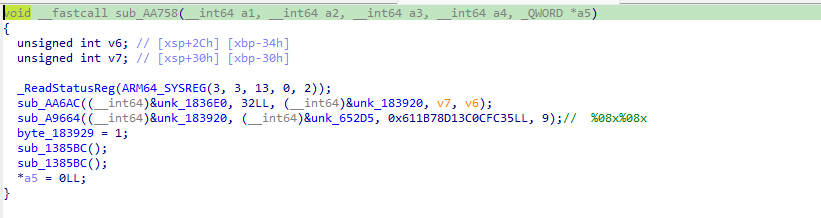
var pthread_create = Module.findExportByName("libc.so", "pthread_create"); Interceptor.attach(pthread_create, { onEnter: function (args) { var start_routine = args[2];
defpart2_suffix(token): raw = token_ascii + token_ascii
# sub_AA9B0, 注意不是普通 IV XOR block = [] for i inrange(16): if i & 1: block.append(raw[i] ^ IV[i]) else: block.append(raw[i] ^ IV[15 - i])
# sub_A8D44 state = block ^ PRE_XOR state = add_round_key(state, 0)
for r inrange(1, 11): state = sub_bytes(state) state = round_tweak(state, r) state = shift_rows(state) state = mix_columns(state) state = add_round_key(state, r)
state = sub_bytes(state) state = round_tweak(state, 11) state = shift_rows(state) state = add_round_key(state, 11) state = state ^ POST_XOR
""" Stage A: Unicorn-based offline emulator for sub_A9A7C in libsec2026.so. Goal: given an 8-char hex token, call sub_A9A7C and return its 16-char suffix, producing the same result as running the .so on-device. No Frida, no phone, no anti-debug concerns. Usage: python emulate_sub_A9A7C.py 12345678 Expected outputs (validation set): 12345678 -> 7b84d2118e34500f abcdef01 -> b9360ac9ff33cdc7 4aca4699 -> 224bbbfc6eadbf92 """ import os import sys import struct from unicorn import Uc, UC_ARCH_ARM64, UC_MODE_ARM, UcError from unicorn import UC_PROT_READ, UC_PROT_WRITE, UC_PROT_EXEC from unicorn import UC_HOOK_CODE, UC_HOOK_MEM_INVALID, UC_HOOK_MEM_READ_UNMAPPED, UC_HOOK_MEM_WRITE_UNMAPPED, UC_HOOK_INTR from unicorn.arm64_const import * from elftools.elf.elffile import ELFFile
# ============================================================ classFakeLibc: """Stubs for the libc functions referenced by libsec2026.so.""" def__init__(self, emu): self.emu = emu self.heap_ptr = HEAP_BASE # each stub is 8 bytes of code: RET (0xd65f03c0 little-endian). # We don't actually rely on those bytes — we hook by address — but # having a RET is a safe fallback if a hook ever misses. self.names = [ "pthread_mutex_lock", "pthread_mutex_unlock", "pthread_create", "malloc", "free", "memcpy", "memset", "memmove", "strlen", "strcmp", "strncmp", "strcpy", "strncpy", "strchr", "__memcpy_chk", "__memset_chk", "__memmove_chk", "__strcpy_chk", "__strncpy_chk", "__strcat_chk", "__stack_chk_fail", "__cxa_finalize", "__cxa_atexit", "abort", "exit", ] self.addr_of = {} for i, n inenumerate(self.names): self.addr_of[n] = STUB_BASE + i * 0x10 self.name_of = {v: k for k, v inself.addr_of.items()}
definstall(self, uc): # write a `RET` at each stub address as safety net ret_code = struct.pack("<I", 0xD65F03C0) # RET for addr inself.addr_of.values(): uc.mem_write(addr, ret_code)
defon_hit(self, uc, addr): """Called when PC enters a stub address. Simulate the libc call and return by setting PC = LR.""" name = self.name_of[addr] x0 = uc.reg_read(UC_ARM64_REG_X0) x1 = uc.reg_read(UC_ARM64_REG_X1) x2 = uc.reg_read(UC_ARM64_REG_X2) x3 = uc.reg_read(UC_ARM64_REG_X3) lr = uc.reg_read(UC_ARM64_REG_LR)
if name == "pthread_mutex_lock"or name == "pthread_mutex_unlock": uc.reg_write(UC_ARM64_REG_X0, 0) elif name == "pthread_create": # X0 = thread_t *out, X2 = start_routine, X3 = arg # Anti-debug threads - just pretend success without launching. # Write a fake thread handle to *X0. if x0: try: uc.mem_write(x0, b"\x00" * 8) except UcError: pass uc.reg_write(UC_ARM64_REG_X0, 0) elif name == "malloc": size = x0 # 16-byte align size = (size + 15) & ~15 p = self.heap_ptr self.heap_ptr += size ifself.heap_ptr > HEAP_BASE + HEAP_SIZE: raise RuntimeError("heap exhausted") # zero it (malloc doesn't, but safer) uc.mem_write(p, b"\x00" * size) uc.reg_write(UC_ARM64_REG_X0, p) elif name == "free": pass# no-op elif name == "memcpy"or name == "memmove"or name == "__memcpy_chk"or name == "__memmove_chk": dst, src, n = x0, x1, x2 if n: data = uc.mem_read(src, n) uc.mem_write(dst, bytes(data)) uc.reg_write(UC_ARM64_REG_X0, dst) elif name == "memset"or name == "__memset_chk": dst, c, n = x0, x1 & 0xFF, x2 if n: uc.mem_write(dst, bytes([c]) * n) uc.reg_write(UC_ARM64_REG_X0, dst) elif name == "strcpy"or name == "__strcpy_chk": dst, src = x0, x1 i = 0 whileTrue: b = bytes(uc.mem_read(src + i, 1))[0] uc.mem_write(dst + i, bytes([b])) i += 1 if b == 0: break if i > 0x10000: break uc.reg_write(UC_ARM64_REG_X0, dst) elif name == "strncpy"or name == "__strncpy_chk": dst, src, n = x0, x1, x2 i = 0 hit = False while i < n: ifnot hit: b = bytes(uc.mem_read(src + i, 1))[0] if b == 0: hit = True else: b = 0 uc.mem_write(dst + i, bytes([b])) i += 1 uc.reg_write(UC_ARM64_REG_X0, dst) elif name == "__strcat_chk": # dst, src, dst_buf_size dst, src = x0, x1 # find end of dst dl = 0 whilebytes(uc.mem_read(dst + dl, 1))[0] != 0and dl < 0x10000: dl += 1 i = 0 whileTrue: b = bytes(uc.mem_read(src + i, 1))[0] uc.mem_write(dst + dl + i, bytes([b])) i += 1 if b == 0: break if i > 0x10000: break uc.reg_write(UC_ARM64_REG_X0, dst) elif name == "strchr": s, c = x0, x1 & 0xFF i = 0 found = 0 whileTrue: b = bytes(uc.mem_read(s + i, 1))[0] if b == c: found = s + i; break if b == 0: break i += 1 if i > 0x10000: break uc.reg_write(UC_ARM64_REG_X0, found) elif name == "strlen": s = x0 L = 0 whileTrue: b = bytes(uc.mem_read(s + L, 1))[0] if b == 0: break L += 1 if L > 0x10000: break uc.reg_write(UC_ARM64_REG_X0, L) elif name == "strcmp": s1, s2 = x0, x1 for i inrange(0x10000): a = bytes(uc.mem_read(s1 + i, 1))[0] b = bytes(uc.mem_read(s2 + i, 1))[0] if a != b: uc.reg_write(UC_ARM64_REG_X0, (a - b) & 0xFFFFFFFFFFFFFFFF) break if a == 0: uc.reg_write(UC_ARM64_REG_X0, 0) break elif name == "strncmp": s1, s2, n = x0, x1, x2 rv = 0 for i inrange(n): a = bytes(uc.mem_read(s1 + i, 1))[0] b = bytes(uc.mem_read(s2 + i, 1))[0] if a != b: rv = (a - b) & 0xFFFFFFFFFFFFFFFF; break if a == 0: break uc.reg_write(UC_ARM64_REG_X0, rv) elif name == "__stack_chk_fail": raise RuntimeError("__stack_chk_fail invoked — canary mismatch") elif name == "abort"or name == "exit": raise RuntimeError(f"{name}() invoked, LR=0x{lr:x}") elif name in ("__cxa_finalize", "__cxa_atexit"): uc.reg_write(UC_ARM64_REG_X0, 0) else: raise RuntimeError("unhandled stub: " + name)
def_load_segments(self): uc = self.uc withopen(self.so_path, "rb") as f: elf = ELFFile(f) self.dynsym = elf.get_section_by_name(".dynsym") # load PT_LOAD for seg in elf.iter_segments(): if seg.header.p_type != "PT_LOAD": continue va = seg.header.p_vaddr data = seg.data() memsz = seg.header.p_memsz # write file data uc.mem_write(LIB_BASE + va, data) # zero-fill up to memsz (BSS) if memsz > len(data): uc.mem_write(LIB_BASE + va + len(data), b"\x00" * (memsz - len(data)))
def_apply_relocations(self): uc = self.uc withopen(self.so_path, "rb") as f: elf = ELFFile(f) dynsym = elf.get_section_by_name(".dynsym") total = applied = unresolved_funcs = 0 for sec_name in (".rela.dyn", ".rela.plt"): sec = elf.get_section_by_name(sec_name) if sec isNone: continue for rel in sec.iter_relocations(): total += 1 r_off = rel.entry.r_offset r_type = rel.entry.r_info_type r_addend = rel.entry.r_addend r_sym = rel.entry.r_info_sym addr = LIB_BASE + r_off if r_type == R_AARCH64_RELATIVE: val = LIB_BASE + r_addend uc.mem_write(addr, struct.pack("<Q", val)) applied += 1 elif r_type in (R_AARCH64_GLOB_DAT, R_AARCH64_JUMP_SLOT, R_AARCH64_ABS64): sym = dynsym.get_symbol(r_sym) name = sym.name if sym.entry.st_shndx != "SHN_UNDEF": # internal symbol val = LIB_BASE + sym.entry.st_value + r_addend else: if name inself.libc.addr_of: val = self.libc.addr_of[name] else: # unresolved external — write a unique stub addr so we # detect it if ever called. val = STUB_BASE + 0x8000 + (r_sym * 8) if name: self.unresolved_stub_hits[val] = name unresolved_funcs += 1 uc.mem_write(addr, struct.pack("<Q", val)) applied += 1 else: # unknown type — skip; not expected to matter for our target. pass ifself.verbose: print(f"[reloc] total={total} applied={applied} " f"unresolved_ext_funcs={unresolved_funcs}")
def_hook_sub_AA6AC(self, uc, address, size, user_data): """Emulate `sub_AA6AC(dst=X0, dst_size=X1, fmt=X2, ...varargs...)` as a snprintf-like call.""" dst = uc.reg_read(UC_ARM64_REG_X0) dstsize = uc.reg_read(UC_ARM64_REG_X1) & 0xFFFFFFFF fmt_ptr = uc.reg_read(UC_ARM64_REG_X2) lr = uc.reg_read(UC_ARM64_REG_LR) # read up to 256 bytes of fmt raw = bytes(uc.mem_read(fmt_ptr, 256)) nul = raw.find(b"\x00") if nul >= 0: raw = raw[:nul] fmt = raw.decode("latin-1", errors="replace")
# collect a pool of integer varargs: X3..X7 then from stack ireg = [uc.reg_read(r) for r in (UC_ARM64_REG_X3, UC_ARM64_REG_X4, UC_ARM64_REG_X5, UC_ARM64_REG_X6, UC_ARM64_REG_X7)] # additional varargs on stack, if any sp = uc.reg_read(UC_ARM64_REG_SP) stack_vals = [] try: stack_raw = bytes(uc.mem_read(sp, 0x80)) for i inrange(0, len(stack_raw), 8): stack_vals.append(struct.unpack_from("<Q", stack_raw, i)[0]) except UcError: pass arg_pool = ireg + stack_vals
# Minimal printf implementation handling %s, %d, %u, %x, %X, %02x, # %c, %% . No floats expected. out = [] i = 0; ai = 0 while i < len(fmt): c = fmt[i]; i += 1 if c != '%': out.append(c); continue # parse flags/width/precision (width/prec only) spec = '' while i < len(fmt) and fmt[i] in'0123456789#-+ .': spec += fmt[i]; i += 1 if i >= len(fmt): break conv = fmt[i]; i += 1 if conv == 'l': # skip length modifiers if i < len(fmt) and fmt[i] == 'l': i += 1 conv = fmt[i]; i += 1 if conv == '%': out.append('%'); continue if conv == 's': p = arg_pool[ai]; ai += 1 if p == 0: out.append("(null)") else: buf = bytes(uc.mem_read(p, 0x200)) z = buf.find(b"\x00") out.append(buf[:z if z >= 0else0x200].decode("latin-1", errors="replace")) continue if conv in ('d','i'): v = arg_pool[ai]; ai += 1 # sign-extend 32-bit v32 = v & 0xFFFFFFFF if v32 & 0x80000000: v32 -= 0x100000000 out.append(("%"+spec+"d") % v32); continue if conv in ('u',): v = arg_pool[ai]; ai += 1 out.append(("%"+spec+"u") % (v & 0xFFFFFFFF)); continue if conv in ('x','X'): v = arg_pool[ai]; ai += 1 out.append(("%"+spec+conv) % (v & 0xFFFFFFFF)); continue if conv == 'c': v = arg_pool[ai]; ai += 1 out.append(chr(v & 0xFF)); continue if conv == 'p': v = arg_pool[ai]; ai += 1 out.append("0x%x" % (v & 0xFFFFFFFFFFFFFFFF)); continue # unknown, emit literally out.append('%'+spec+conv)
s = "".join(out) enc = s.encode("latin-1", errors="replace") enc = enc[:max(0, dstsize - 1)] try: uc.mem_write(dst, enc + b"\x00") except UcError as e: print(f"[sub_AA6AC hook] failed to write dst=0x{dst:x}: {e}")
# ---------- execute ---------- defcall_sub_A9A7C(self, token_bytes): uc = self.uc assertlen(token_bytes) == 8 # write input at IO_BASE+0x100, terminate with a lot of zeros in_addr = IO_BASE + 0x100 uc.mem_write(in_addr, token_bytes + b"\x00" * 32) # set up registers sp = STACK_BASE + STACK_SIZE - 0x100 uc.reg_write(UC_ARM64_REG_SP, sp) uc.reg_write(UC_ARM64_REG_X0, in_addr) uc.reg_write(UC_ARM64_REG_LR, RETURN_SENTINEL)
start_pc = LIB_BASE + SUB_A9A7C # run with a big instruction budget try: uc.emu_start(start_pc, RETURN_SENTINEL, timeout=0, count=0) except UcError as e: pc = uc.reg_read(UC_ARM64_REG_PC) print(f"[UcError] {e} PC=0x{pc:x} libOff=0x{pc-LIB_BASE:x}") raise
# X0 holds the return pointer — read a C-string from it out_ptr = uc.reg_read(UC_ARM64_REG_X0) if out_ptr == 0: returnNone # read up to 64 bytes raw = bytes(uc.mem_read(out_ptr, 64)) nul = raw.find(b"\x00") if nul >= 0: raw = raw[:nul] return raw.decode("latin-1", errors="replace")
emu = Emulator(SO_PATH, verbose=True) for tok, expected in tests: print(f"\n=== token={tok} expected={expected} ===") res = emu.call_sub_A9A7C(tok.encode("ascii")) ok = (expected isNone) or (res == expected) print(f" suffix = {res!r}{'OK'if ok else'WRONG'}")
""" Derive full semantics of every (op,sub) pair by observing register-file and memory diffs from a native trace. For each opcode, record pre/post state of all 32 regs, all VM memory, and the decoded operands. Then analyze. """ import os, sys, struct, json, pickle from collections import defaultdict sys.path.insert(0, os.path.dirname(os.path.abspath(__file__))) from emulate_sub_A9A7C import Emulator, SO_PATH, LIB_BASE, HEAP_BASE from unicorn.arm64_const import * from vm_disasm_v2 import disasm_one
defrun_and_log(token, max_steps=None): """Step one instruction at a time in native, snapshot regs+mem.""" emu = Emulator(SO_PATH, verbose=False) h0 = [None]; events = [] last_snapshot = [None] # (pc, ins, rf, mem)
orig = emu.libc.on_hit defpatched(uc, addr): name = emu.libc.name_of[addr] if name in ("memcpy","memmove","__memcpy_chk","__memmove_chk"): dst = uc.reg_read(UC_ARM64_REG_X0) src = uc.reg_read(UC_ARM64_REG_X1) n = uc.reg_read(UC_ARM64_REG_X2) if n == BC_LEN and src == LIB_BASE + BC_FILE_OFF and h0[0] isNone: h0[0] = dst if h0[0] isnotNoneand h0[0] <= src < h0[0] + BC_LEN: pc = src - h0[0] d = disasm_one(bc, pc) if d isNone: orig(uc,addr); return ilen, ins = d # close previous event (post-state of last ins) if last_snapshot[0] isnotNone: ppc, pins, prf, _ = last_snapshot[0] post_rf = bytes(uc.mem_read(RF_BASE, 32*8)) # Only snapshot a window of VM mem that might change post_mem = bytes(uc.mem_read(h0[0] + 0x10000, 0x10000)) events.append({"pc": ppc, "ins": pins, "len": pins.get("_len", ilen), "pre_rf": prf, "post_rf": post_rf, "pre_mem": last_snapshot[0][3], "post_mem": post_mem}) if max_steps andlen(events) >= max_steps: uc.emu_stop() return pre_rf = bytes(uc.mem_read(RF_BASE, 32*8)) pre_mem = bytes(uc.mem_read(h0[0] + 0x10000, 0x10000)) last_snapshot[0] = (pc, ins, pre_rf, pre_mem) orig(uc, addr) emu.libc.on_hit = patched suf = emu.call_sub_A9A7C(token) return suf, events
defdiff_rf(a, b): out = {} for i inrange(32): va = struct.unpack_from("<Q", a, i*8)[0] vb = struct.unpack_from("<Q", b, i*8)[0] if va != vb: out[i] = (va, vb) return out
defdiff_mem(a, b): out = [] i = 0 while i < len(a): if a[i] != b[i]: j = i while j < len(a) and a[j] != b[j]: j += 1 out.append((0x10000 + i, a[i:j], b[i:j])) i = j else: i += 1 return out
if __name__ == "__main__": print("Running native trace...") suf, events = run_and_log(b"12345678", max_steps=None) print(f"suffix={suf} events={len(events)}") # Group by opcode by_op = defaultdict(list) for e in events: key = (e["ins"]["op"], e["ins"]["sub"]) by_op[key].append(e)
print(f"\nUnique opcodes seen: {len(by_op)}") for key insorted(by_op.keys()): # pick an example that has mem changes if possible examples = by_op[key] ex = next((e for e in examples if diff_mem(e["pre_mem"], e["post_mem"])), examples[0]) ops = ex["ins"]["operands"] drf = diff_rf(ex["pre_rf"], ex["post_rf"]) dmem = diff_mem(ex["pre_mem"], ex["post_mem"]) # format pre-values of operand regs too pre_vals = {} for t, v in ops: if t == 'r': pre_vals[v] = struct.unpack_from("<Q", ex["pre_rf"], v*8)[0] rf_str = ", ".join(f"r{i:02x}:{a:x}->{b:x}"for i,(a,b) in drf.items() if i != 0x12) mem_str = " | ".join(f"@{a:05x}:{pb.hex()}->{nb.hex()}"for a,pb,nb in dmem[:3]) print(f"\n OP_{key[0]:02x}_{key[1]:02x} count={len(by_op[key])} len={ex['ins'].get('_len','?')}") print(f" ex-operands: {ops} pre-vals: {pre_vals}") print(f" pc=0x{ex['pc']:04x} rf_diff: {rf_str}") if dmem: print(f" mem_diff: {mem_str}")
""" Proper VM disassembler based on the discovered instruction encoding. Instruction format: [op:1] [sub:1] [pad=00:1] [n_operands:1] [operand]* operand = [type:1] [value: 1B if type=01, 4B if type=04] We walk the whole 5414-byte bytecode starting from pc=0 and list every instruction. We also build an instruction-set summary by (op, sub) pair. """ import os, sys, struct, collections
HERE = os.path.dirname(os.path.abspath(__file__)) BC_PATH = os.path.join(HERE, "..", "unk_63DA0_bytecode.bin")
defdisasm_one(bc: bytes, pc: int): """Return (length, structured_instr) or None if malformed.""" if pc + 4 > len(bc): returnNone op, sub, pad, nops = bc[pc], bc[pc + 1], bc[pc + 2], bc[pc + 3] # pad can be 0x00 or 0x20 (flag byte); don't gate on it # parse operands operands = [] cur = pc + 4 for _ inrange(nops): if cur >= len(bc): returnNone t = bc[cur]; cur += 1 if t == 0x01: if cur >= len(bc): returnNone v = bc[cur]; cur += 1 operands.append(('r', v)) elif t == 0x04: if cur + 4 > len(bc): returnNone v = struct.unpack_from("<I", bc, cur)[0]; cur += 4 operands.append(('imm', v)) elif t == 0x08: # not yet seen — guess 8-byte value if cur + 8 > len(bc): returnNone v = struct.unpack_from("<Q", bc, cur)[0]; cur += 8 operands.append(('imm64', v)) else: # unknown operand type returnNone return (cur - pc, {"pc": pc, "op": op, "sub": sub, "nops": nops, "operands": operands})
deffmt_instr(ins): ops = [] for t, v in ins["operands"]: if t == "r": ops.append(f"r{v:02x}") elif t == "imm": ops.append(f"#0x{v:x}") else: ops.append(f"{t}:{v}") returnf"OP_{ins['op']:02x}_{ins['sub']:02x}({', '.join(ops)})"
# Try walking from pc=0. # From the existing static disasm we see pc=0 starts with a 32-byte header # that isn't a valid instruction (table-like data). Look at the # vm_disasm listing: first valid pc with coherent instruction is ~0x009. # Actually looking again: pc=0 seems to have "00 04 00 01" which would # decode as op=0, sub=4, 1 operand (bad perhaps). Let me check.
# Print first 64 bytes print(f" first64: {bc[:64].hex()}")
# Disassemble from pc=0 with auto-resync. all_ins = [] pc = 0 bad = 0 while pc < len(bc): r = disasm_one(bc, pc) if r isNone: # skip a byte and resync bad += 1 pc += 1 continue length, ins = r all_ins.append(ins) pc += length
# Dump full listing out = os.path.join(HERE, "vm_disasm_v2.txt") withopen(out, "w") as f: pc = 0 for ins in all_ins: f.write(f"pc=0x{ins['pc']:04x}{fmt_instr(ins)}\n") print(f"[+] full disasm written: {out} ({len(all_ins)} instructions)")
""" Pure-Python VM interpreter for the bytecode in unk_63DA0_bytecode.bin. Validated by diffing against the native Unicorn emulator. Opcode semantics (empirically derived): ARITHMETIC (sub=01, sub=02) 00_01(d,a,b) d = (a + b) & 0xFFFFFFFF ADD 02_01(d,a,b) d = (a - b) & 0xFFFFFFFF SUB 01_02(d,a,b) d = (a | b) OR 02_02(d,a,b) d = (a ^ b) XOR 04_02(d,a,b) d = (a << (b & 0x3f)) & 0xFFFFFFFF SHL 09_02(d,a,b) d = a & 0xFFFFFFFF TRUNC32 MOV / IMM / CTRL (sub=03, sub=04) 00_03(d,s) d = s MOV 06_03(d,imm32) d = imm32 LOAD_IMM 03_03(r) SP -= 8; mem[SP] = r PUSH 04_03(r) r = mem[SP]; SP += 8 POP 01_03(src,ptr) *(u32*)ptr = src STORE_U32 02_03(src,ptr) *(u32*)ptr = src STORE_U32 (alternate) 00_04(imm) PC = imm JMP 01_04(imm) (?) CALL imm; r14=retPC; PC=imm 04_04(imm) PC = imm JMP (back-edge) 07_04(a,b) flags = a ? b : b CMP/branch? SPECIAL (sub=05, sub=07, sub=08, sub=09, sub=00) 00_05() no-op / loop-head marker 01_05() no-op / loop-exit marker 05_05(imm) no-op? 06_05(r) (?) set-condition 00_07() no-op (called at pc=0x5a and 0x9) 01_07() no-op (called at pc=0x32) 00_09(d,imm) d = alloca(imm) — first call returns 0x17008, incremented by the imm size 01_09(d,ptr,idx) d = *(u8*)(ptr + idx) LOAD_U8 04_09(ptr,val) *(u8*)ptr = val & 0xff STORE_U8 (but destination is a POP address?) 03_08(r,imm) (?) 02_00(imm,imm) native syscall (token in / result out) We will refine via diff with the native trace. """ import os, sys, struct sys.path.insert(0, os.path.dirname(os.path.abspath(__file__))) from vm_disasm_v2 import disasm_one
HERE = os.path.dirname(os.path.abspath(__file__)) BC = open(os.path.join(HERE, "..", "unk_63DA0_bytecode.bin"), "rb").read() VM_BASE = 0x10000 VM_SIZE = 0x10000
classVM: def__init__(self, token: bytes): assertlen(token) == 8 self.mem = bytearray(VM_SIZE) # load bytecode at VM 0x10000 self.mem[0x0:len(BC)] = BC # initial state self.reg = [0] * 32 self.reg[0x10] = 0x1d000# SP self.reg[0x11] = 0x1d000# FP / stack base self.reg[0x12] = 0x10000# PC self.alloca_cursor = 0x17008 self.token = token self.halted = False self.output = None# (x3, x4) self.flag = False# NE-flag: true if last compare "not-equal" self.cmp_eq = False self.cmp_lt = False
# -- memory helpers (VM offset, always within [0, 0x10000) ) -- def_off(self, addr): return addr - VM_BASE # we keep mem indexed by VM-offset
defrd_u8(self, a): returnself.mem[self._off(a)] defrd_u32(self, a): o = self._off(a) return struct.unpack_from("<I", self.mem, o)[0] defrd_u64(self, a): o = self._off(a) return struct.unpack_from("<Q", self.mem, o)[0] defwr_u8(self, a, v): self.mem[self._off(a)] = v & 0xff defwr_u32(self, a, v): struct.pack_into("<I", self.mem, self._off(a), v & 0xFFFFFFFF) defwr_u64(self, a, v): struct.pack_into("<Q", self.mem, self._off(a), v & 0xFFFFFFFFFFFFFFFF)
# operand resolution defval(self, operand, regs=None): t, v = operand if t == 'r': return (regs orself.reg)[v] return v # imm
# NATIVE syscall emulation defsyscall(self, fn_id, nargs): if fn_id == 0x65: # inject token bytes to VM 0x17018, 0x17020, ..., 0x17050 (stride 8, only LSB) for i, b inenumerate(self.token): self.wr_u64(0x17018 + 8*i, b) elif fn_id == 0x66: # read output from registers: X3 = r0c (u32), X4 = r0e (u32) self.output = (self.reg[0x0c] & 0xFFFFFFFF, self.reg[0x0e] & 0xFFFFFFFF) self.halted = True# stop after this else: raise NotImplementedError(f"syscall fn={fn_id:#x}")
"""Lockstep-compare pure-Python VM against native emulator. Report first divergence of regfile state.""" import os, sys, struct sys.path.insert(0, os.path.dirname(os.path.abspath(__file__))) from emulate_sub_A9A7C import Emulator, SO_PATH, LIB_BASE, HEAP_BASE from unicorn.arm64_const import * from vm_disasm_v2 import disasm_one from vm_interpret import VM
"""Validate vm_interpret.py against native emulator with many random tokens.""" import os, sys, random, string sys.path.insert(0, os.path.dirname(os.path.abspath(__file__))) from vm_interpret import VM, format_suffix sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) from compute_suffix import compute_suffix
random.seed(2026) ok = 0; bad = 0 chars = string.hexdigits.lower()[:16] for i inrange(30): tok = ''.join(random.choices(chars, k=8)).encode() vm = VM(tok) got = format_suffix(vm.run()) exp = compute_suffix(tok.decode()) if got == exp: ok += 1 else: bad += 1 print(f"DIFF token={tok} got={got} exp={exp}") print(f"\n{ok}/{ok+bad} passed")
30 条随机 token 全部和 native 一致。Python VM 验毕。
此时已经可以”完全脱离 Unicorn”运行。但这还是解释器,不是算法。
4. 第四阶段:识别循环结构
4.1 找循环头
代码实现如下
pc_hist.py
1 2 3 4 5 6 7 8 9
from collections import Counter from vm_interpret import VM vm = VM(b"12345678") counts = Counter() whilenot vm.halted: counts[vm.reg[0x12]] += 1 vm.step() for pc, n in counts.most_common(20): print(f" pc=0x{pc:x} count={n}")
""" Trace the high-level algorithm: dump relevant registers at each iteration of the 28-round loop (pc=0x07bb is the loop head). """ import os, sys sys.path.insert(0, os.path.dirname(os.path.abspath(__file__))) from vm_interpret import VM, format_suffix
deftrace_loop(token: bytes): vm = VM(token) iter_log = [] whilenot vm.halted: pc = vm.reg[0x12] # log entry to loop head at pc=0x107bb (VM addr 0x07bb) if pc == 0x107bf: snap = {i: vm.reg[i] & 0xFFFFFFFFfor i inrange(0x20)} iter_log.append(snap) vm.step() return iter_log, format_suffix(vm.output)
for tok in [b"12345678", b"4aca4699"]: log, suf = trace_loop(tok) print(f"\n===== token={tok} suffix={suf} rounds={len(log)} =====") print(f"{'round':>5}{'r00':>9}{'r08':>9}{'r09':>9}{'r0a':>9}{'r0b':>9}{'r0c':>9}{'r0d':>9}{'r0e':>9}") for i, s inenumerate(log): print(f"{i:>5}{s[0x00]:08x}{s[0x08]:08x}{s[0x09]:08x}{s[0x0a]:08x}{s[0x0b]:08x}{s[0x0c]:08x}{s[0x0d]:08x}{s[0x0e]:08x}")
functionhexPattern(s) { var out = []; for (var i = 0; i < s.length; i++) { out.push(("0" + s.charCodeAt(i).toString(16)).slice(-2)); } return out.join(" "); }
functionhexPatternUtf32(s) { var out = []; for (var i = 0; i < s.length; i++) { out.push(("0" + s.charCodeAt(i).toString(16)).slice(-2)); out.push("00"); out.push("00"); out.push("00"); } return out.join(" "); }
functionstartPatchLoop() { // Try immediately; then keep watching early scene/resource load. patchReadableMemory("initial-scan");
var attempts = 0; var timer = setInterval(function () { attempts++; patchReadableMemory("scan-" + attempts); if (attempts >= 40) { clearInterval(timer); console.log("[*] resource patch loop stopped; total patches=" + patchCount); console.log("[*] Now collide with the original Trigger1 block. If patchCount > 0, it should display PART1 via game logic."); } }, 500); }
functionmain() { console.log("[*] PART1 real-trigger script: no libsec2026.so inline hooks"); console.log("[*] Redirecting trigger1.gd/gdc resource path to trigger2.gd/gdc during load"); hookAntiDebug(); hookPathRedirects(); console.log("[*] Heavy memory/read-buffer scanning is disabled during startup."); console.log("[*] If no redirect appears after the scene loads, run: await rpc.exports.patch()"); }
main();
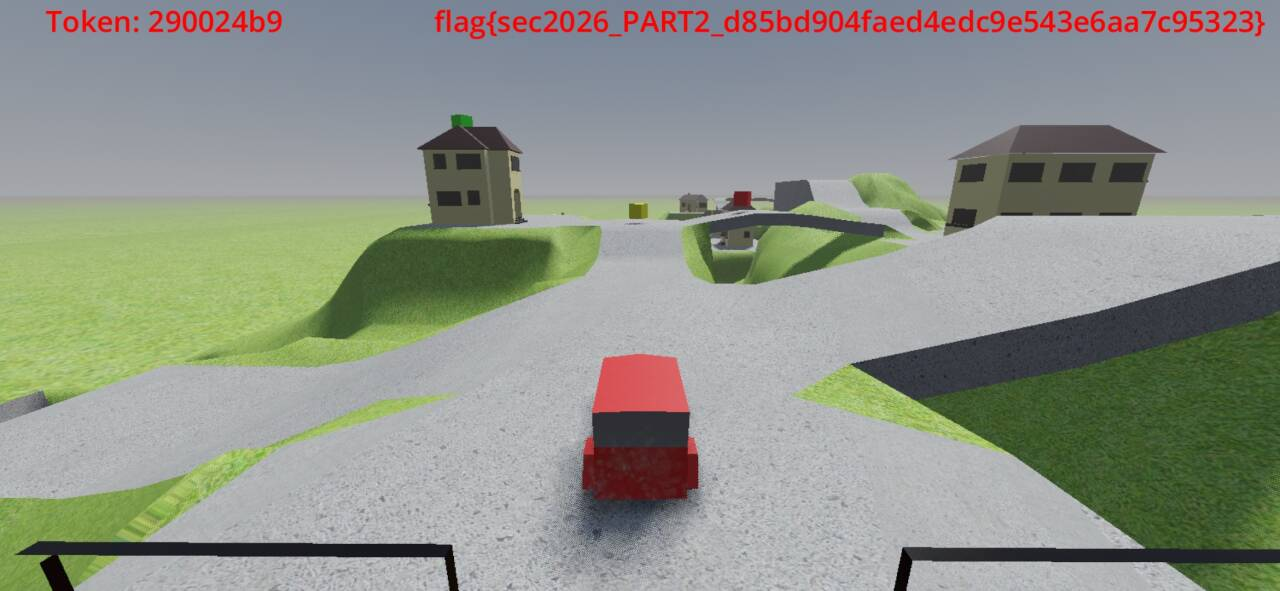
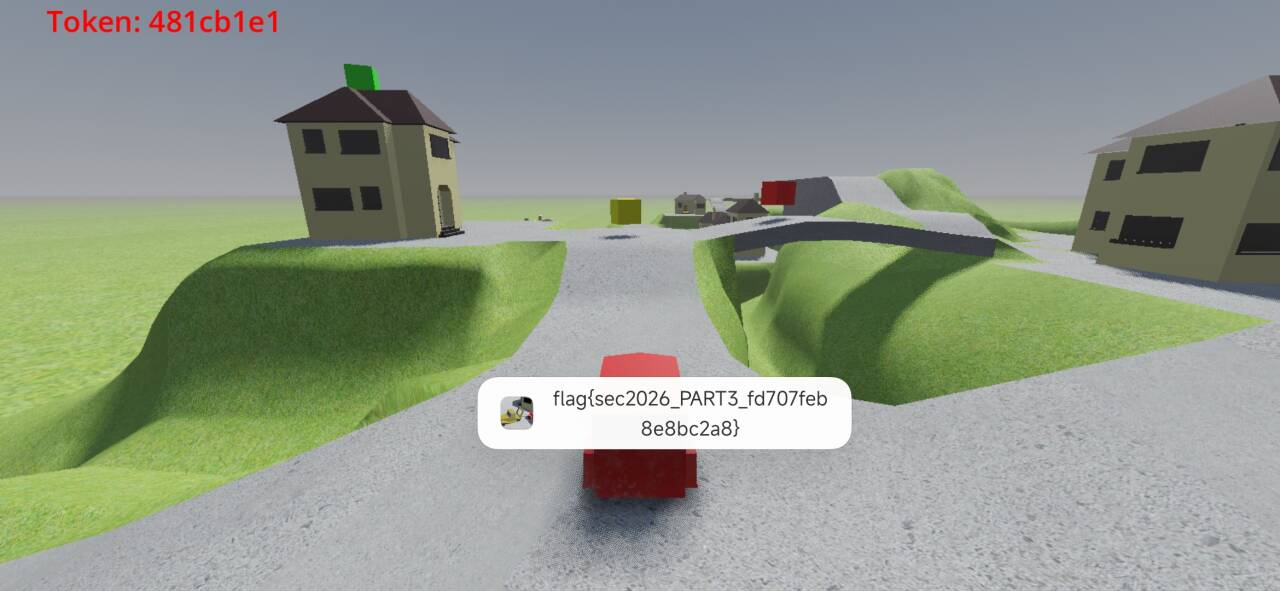
PART2 flag
part2 的 flag 获取思路与 part1 一致,只是重定向被改到 trigger3.gd/gdc 了
functionhexPattern(s) { var out = []; for (var i = 0; i < s.length; i++) { out.push(("0" + s.charCodeAt(i).toString(16)).slice(-2)); } return out.join(" "); }
functionhexPatternUtf32(s) { var out = []; for (var i = 0; i < s.length; i++) { out.push(("0" + s.charCodeAt(i).toString(16)).slice(-2)); out.push("00"); out.push("00"); out.push("00"); } return out.join(" "); }
functionpatchRange(base, size, source) { if (size <= 0 || size > 0x2000000) return0; var local = 0;
for (var i = 0; i < RESOURCE_PATCHES.length; i++) { var p = RESOURCE_PATCHES[i]; try { var hits = Memory.scanSync(base, size, p.pattern); for (var j = 0; j < hits.length; j++) { try { p.write(hits[j].address); local++; patchCount++; console.log("[patch] " + p.name + " -> trigger3 @ " + hits[j].address + " (" + source + ")"); } catch (_e) { } } } catch (_e) { } }
return local; }
functionpatchReadableMemory(source) { var total = 0; scanCount++;
var ranges = Process.enumerateRanges({ protection: "rw-", coalesce: true }); for (var i = 0; i < ranges.length; i++) { var r = ranges[i]; if (r.size < 16 || r.size > 0x2000000) continue; total += patchRange(r.base, r.size, source); }
var attempts = 0; var timer = setInterval(function () { attempts++; patchReadableMemory("scan-" + attempts); if (attempts >= 50) { clearInterval(timer); console.log("[*] resource patch loop stopped; total patches=" + patchCount); console.log("[*] Collide with the original Trigger1 block. If patchCount > 0, it should display PART2 through game logic."); } }, 500); }
functionmain() { console.log("[*] PART2 real-trigger script: no libsec2026.so inline hooks"); console.log("[*] Redirecting trigger1.gd/gdc resource path to trigger3.gd/gdc during load"); hookAntiDebug(); hookPathRedirects(); console.log("[*] Heavy memory/read-buffer scanning is disabled during startup."); console.log("[*] If no redirect appears after the scene loads, run: await rpc.exports.patch()"); }
functionwaitForLibrary() { var mod = Process.findModuleByName(LIB_NAME); if (mod !== null) setLibBase(mod.base); }
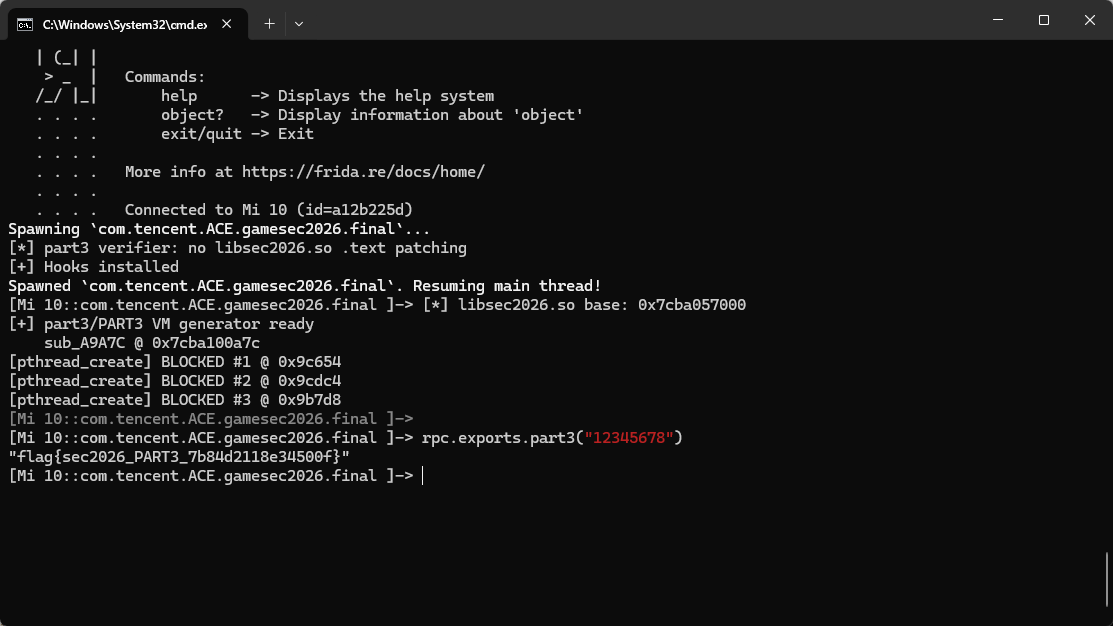
functioncomputepart3Suffix(token) { if (libBase === null || part3Core === null) { thrownewError("libsec2026.so is not ready yet"); } if (!/^[0-9a-fA-F]{8}$/.test(token)) { thrownewError("token must be exactly 8 hex chars"); }
/* * sub_A9A7C copies exactly 8 bytes from this pointer into its native * scratch buffer. NUL termination is harmless and convenient here. */ var inBuf = Memory.allocUtf8String(token); var ret = part3Core(inBuf); if (ret.isNull()) thrownewError("sub_A9A7C returned NULL"); return ret.readCString(); }
functionbuildFlag(token) { /* * Source uses Trigger1..4 mapped to PART0..PART3. The fourth trigger is * therefore PART3 even if we call it "part3" in notes. */ return"flag{sec2026_PART3_" + computepart3Suffix(token) + "}"; }
// Give Godot time to create the label, then scan once. setTimeout(function () { if (Object.keys(shown).length === 0) scanTokenInReadableMemory(); }, 10000);